生成AI周りの知識整理(個人メモ)
生成AIとは
生成AIの種類・できること
- テキスト生成
- 画像生成
- 動画生成
- 音声生成
補足ですが、特定のタスクに特化したAIは「弱いAI」と呼ばれ、一方で人間の知性と同等かそれ以上の汎用的な知的能力・自己意識を持つAIは「強いAI」と呼ばれます。特定のタスクに特化する生成AIはまだまだ弱いAIではありますが、今も目まぐるしい変革を遂げている生成AIはいずれ、強いAIに分類される時が来るかもしれません。
引用: https://www.brainpad.co.jp/doors/contents/about_generative_ai/
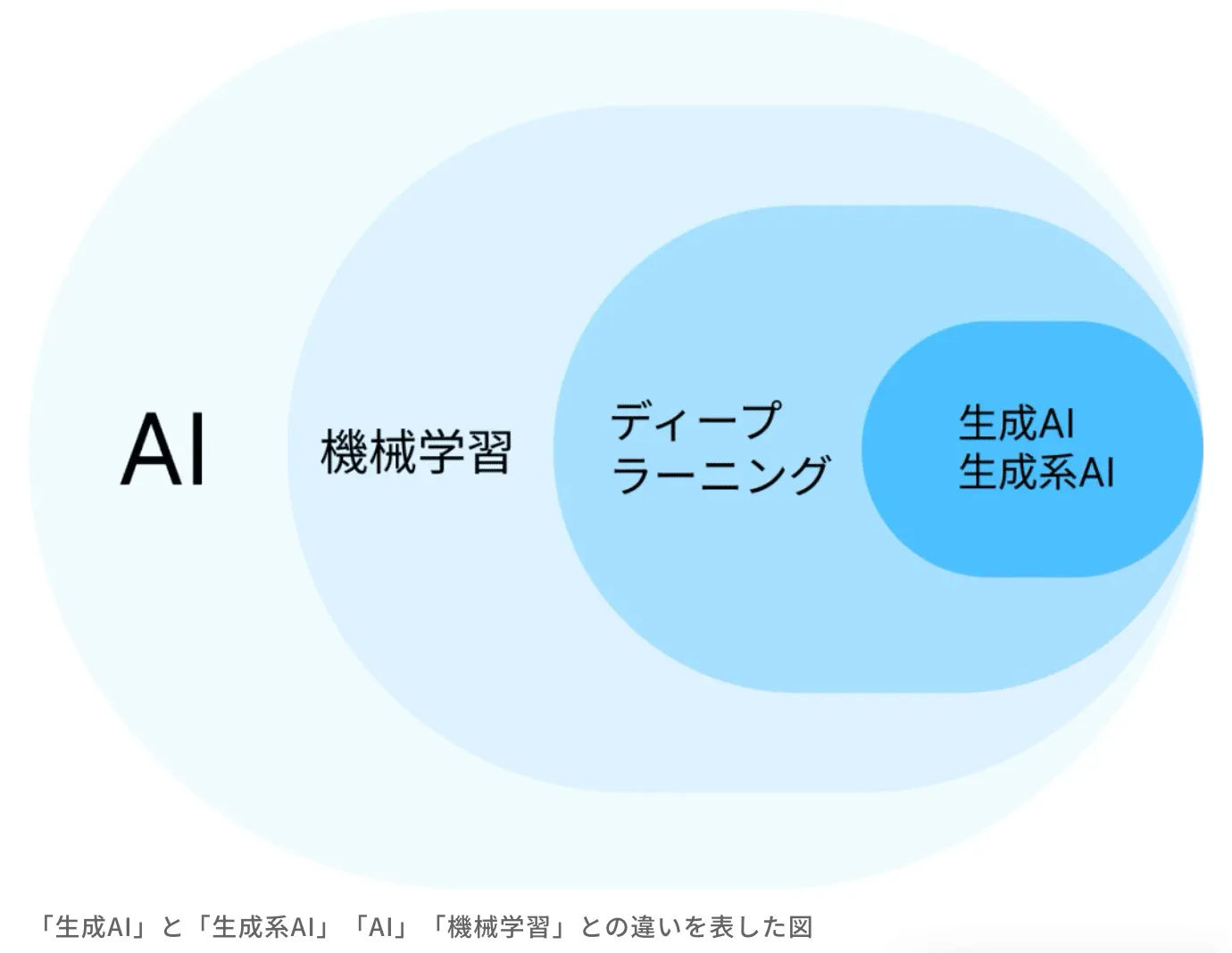
「生成AI」は幅広い意味での「AI」の一部
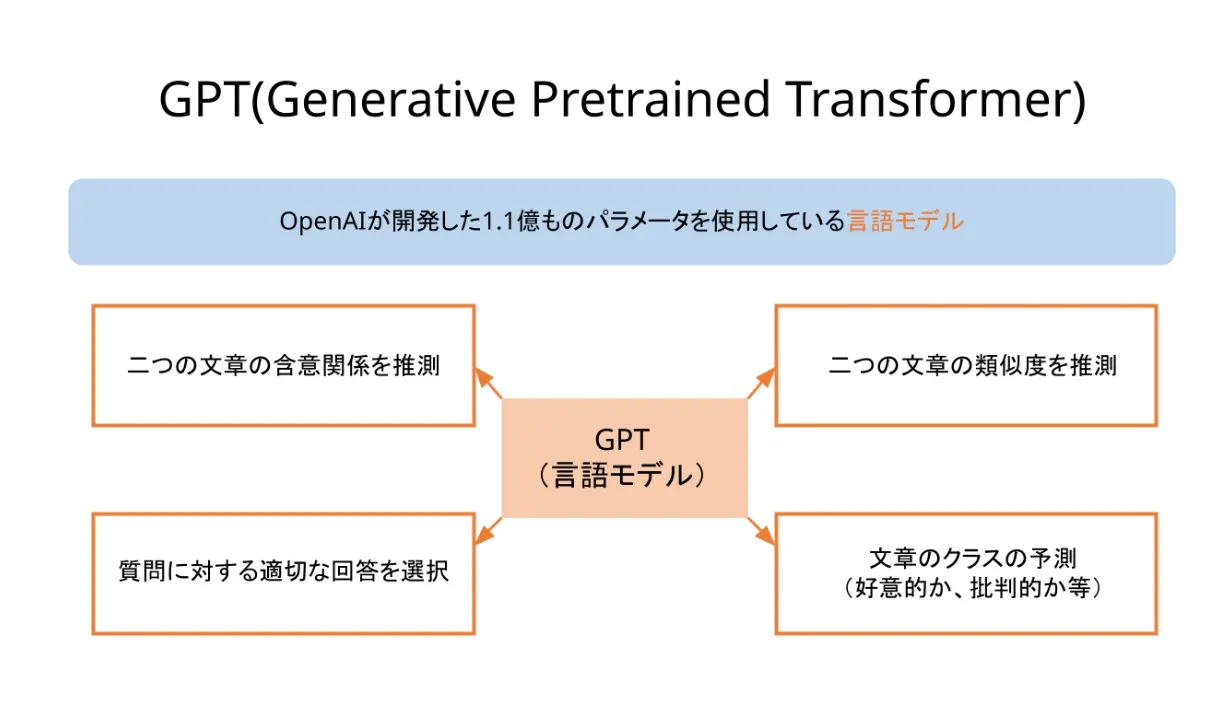
GPT(Generative Pre-Trained Tranceformer)
GPT とはトランスフォーマーアーキテクチャを使用するニューラルネットワークモデルの一種で、ジェネレーティブプレトレーニングトランスフォーマーとも呼ばれます。ChatGPT などの生成系 AI アプリケーションの基礎となっている人工知能 (AI) の重要な新技術です。
引用: https://aws.amazon.com/jp/what-is/gpt/
引用: https://zero2one.jp/ai-word/gpt/
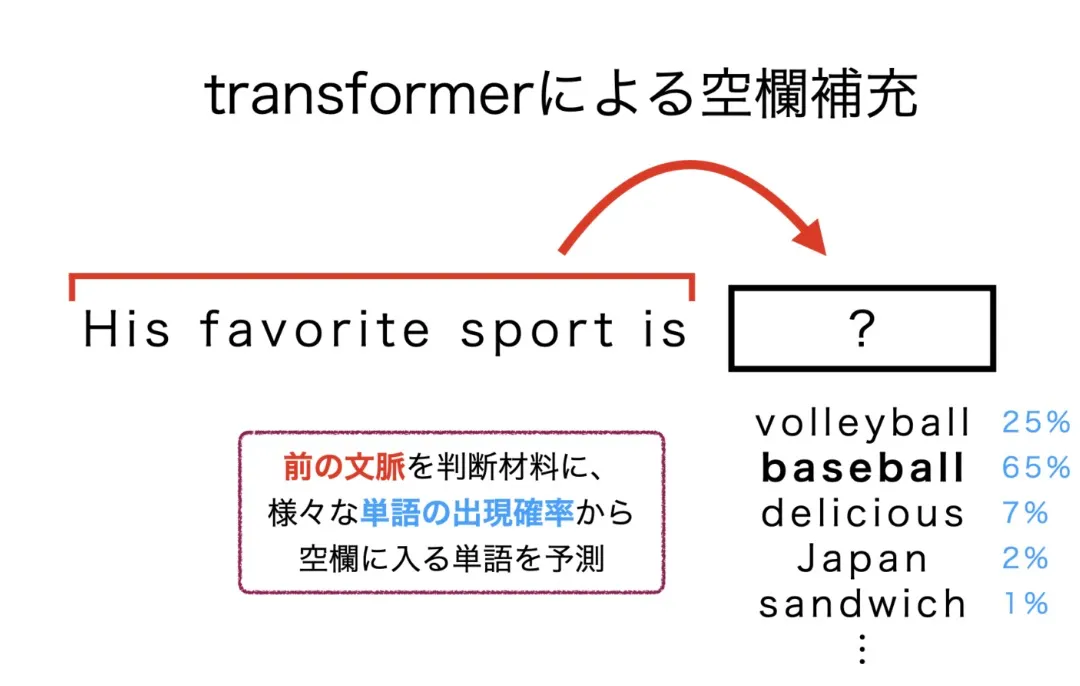
Transformerとは

引用: https://zero2one.jp/ai-word/gpt/
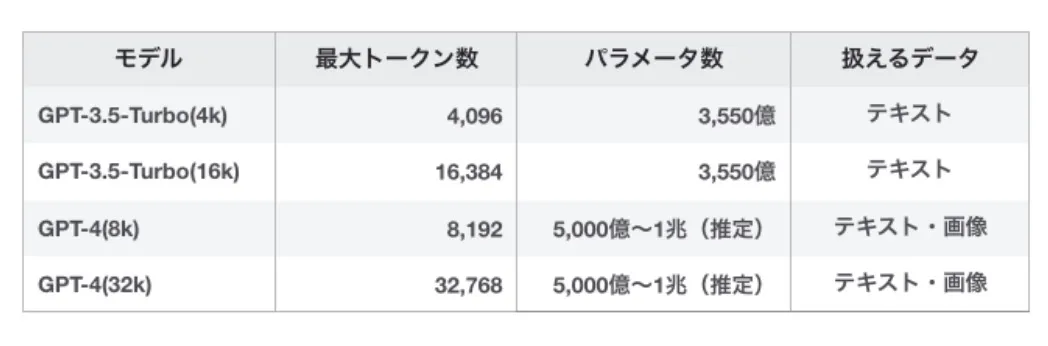
GPTの性能バージョン別性能比較
引用: https://self.systems/laboratory-model-comparison/
GPT-4のパラメータは非公開のため、性能から推定された数値
マルチモーダル
複数の種類や形式のデータに対応する、という意味
GPT-3.5 以前までは難しかった、画像も組み合わせたインプットがGPT-4 以降には可能になった
GPT-4oではマルチモーダル処理性能はさらに向上した
GPT-4oモデルは、GPT-4 Turboモデルをベースに2024年5月13日に発表されたOpenAIの最新かつ最も高度なAIモデルです。GPT-4oモデルは、出力速度、解答の質、対応言語など、前モデルに欠けていた性能も向上しています。GPT-4oは、英語だけでなく、英語以外の言語でも、より高品質で、文法的に正しく、簡潔な出力が可能です。
引用: https://textcortex.com/ja/post/gpt-4o-vs-gpt-4
RAG (Retrival Augmented Generate)
検索によって拡張された生成処理
LLMが持っていない知識をLLM外部の情報ソースとの合わせ技で補い、最終的な回答を作り出す手法。
外部の情報ソースにはよく「ベクトルデータベース」が使用される。
ファインチューニングと違い、LLM自体に知識を持たせるのではなく、LLMとデータベースを連携させる、という手法。
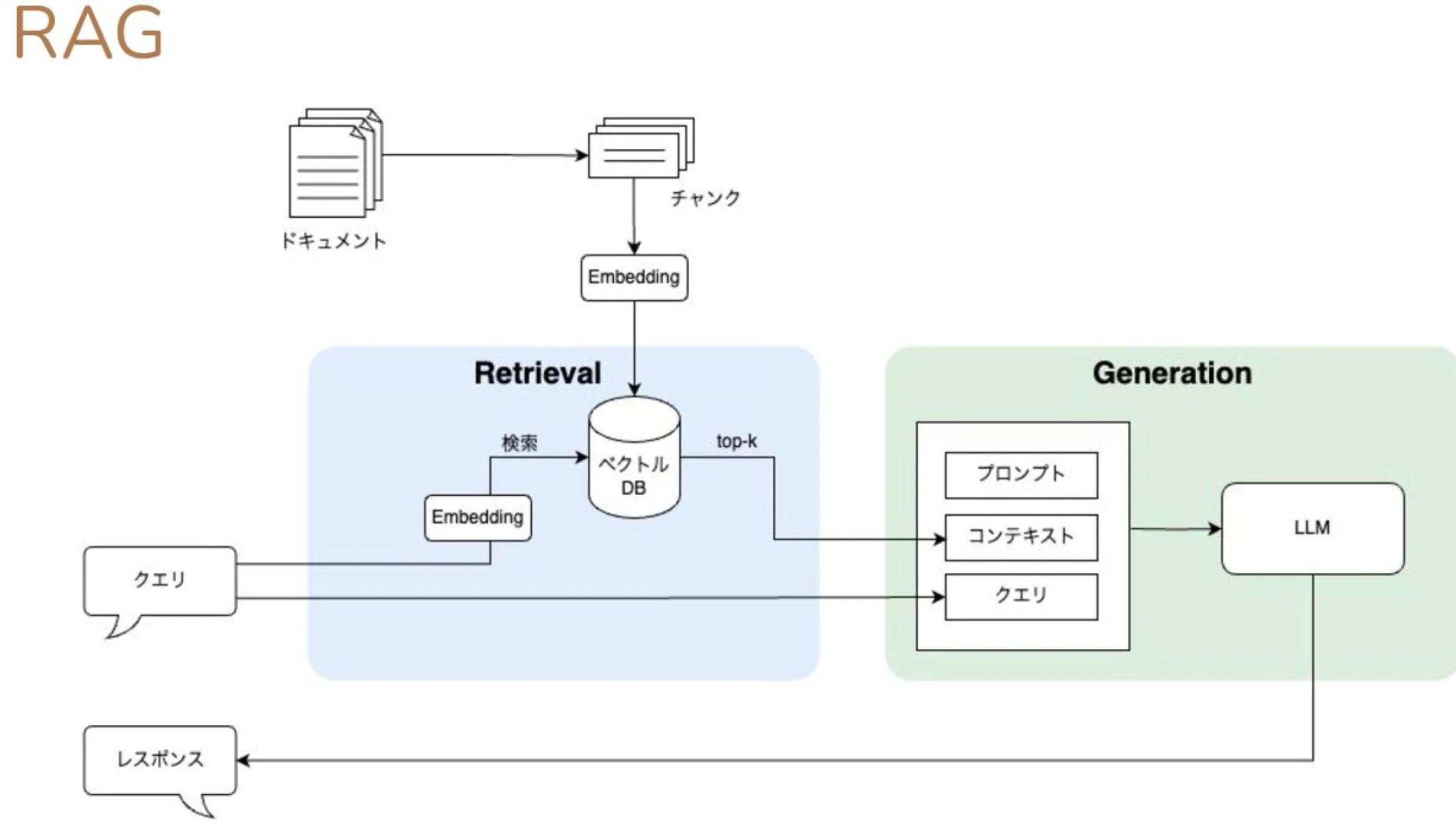
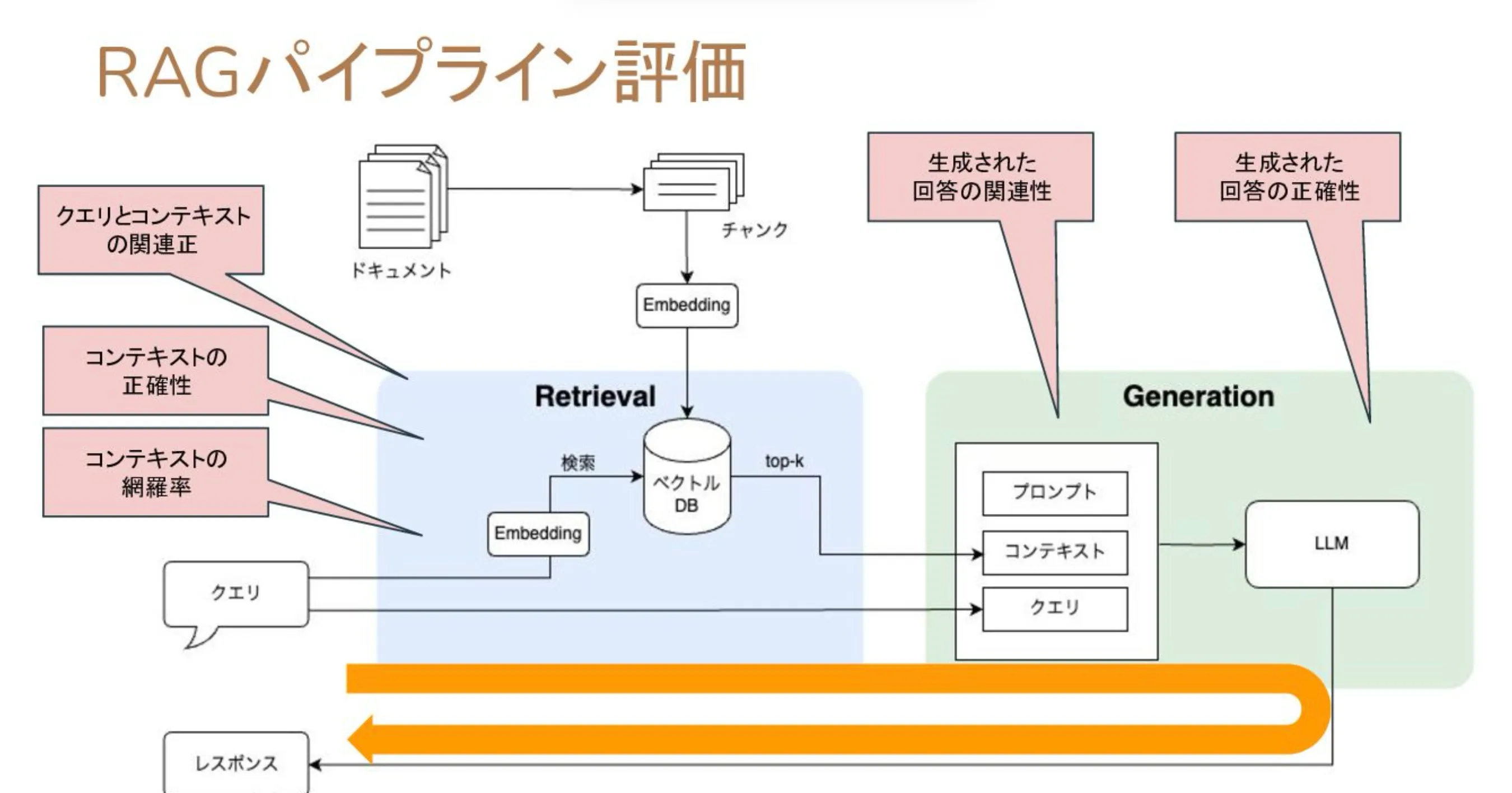
参考: https://speakerdeck.com/kun432/evaluate-retrival-of-rag-using-ranx
https://officebot.jp/columns/ai-tool/rag-structure/#RAG-2
https://www.idnet.co.jp/column/page_308.html
チャンキング
- チャンキングとは、大きなテキストをより小さなセグメントに分割するプロセスのこと
- チャンキングを行う主な理由は、できるだけノイズの少ない、意味的に関連性のあるコンテンツを埋め込むため
- LLMを使ってコンテンツを埋め込むと、ベクトル・データベースから戻ってくるコンテンツの関連性を最適化するのに不可欠なテクニック
引用
https://qiita.com/ymgc3/items/44d1638711dc76f129fd
簡潔に言えば、文章を一つの塊に分けること。
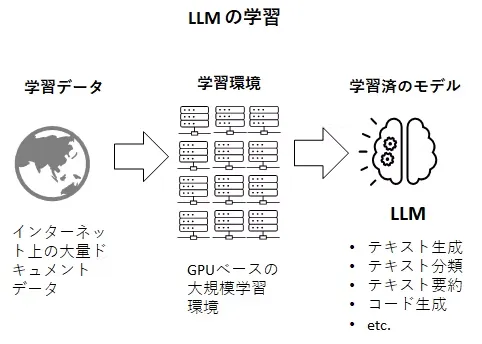
LLMの学習について
LLMそのものは、インターネット上に存在するドキュメントデータをクローリングによって大量に収集し、それを学習データとして機械学習にかけたモデルのこと
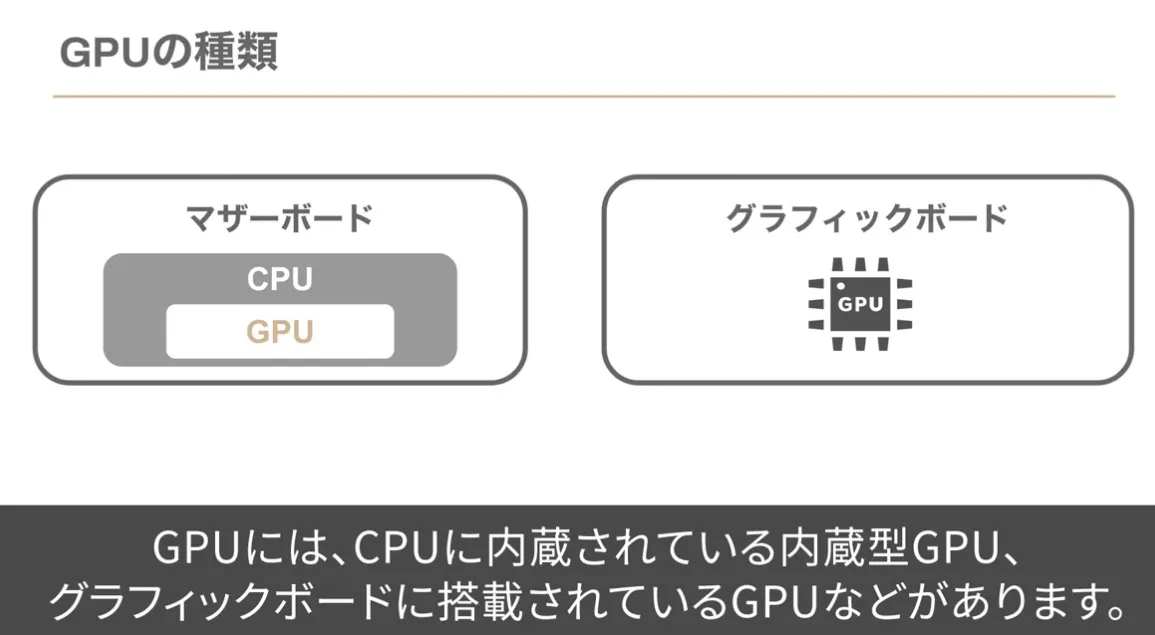
GPUとは
Graphics Processing Unitの略
もともとGPUは画像処理を行う装置だったが、最近ではAI開発に利用されている
なぜAI開発で使用されているのか
- 並列計算能力の高さ
- AIは膨大な演算処理を必要とする
- ディープラーニングにおいては、基本的に中間層の数が多くなるほど複雑な判断ができるようになる
- そのためには大規模な計算が必要
- 従来のコンピュータの計算装置といえば、CPUが主に使用されていたが、最近ではGPUが利用されていることが多い
- CPU取り複雑で多様な処理はできないが、以下の利点がある
- 並列処理
- 同じような計算を高速で繰り返すことができる
- CPU取り複雑で多様な処理はできないが、以下の利点がある
ディープラーニングは「行列計算」を行うが、行列計算には並列計算能力が高いGPUが向いている。画像処理に関わらず言語処理や音声処理にもGPUは使われている。
生成AIで多く採用されているのがNVIDIAのGPUである。
AI関連処理に活用されている半導体であるGPUで8割以上のシェアを占めるNVIDIAは、2023年5月末に半導体メーカーとして初めて株式時価総額が1兆米ドルを突破した。生成AIでの学習処理や推論処理に利用されているチップには、主に同社製GPUの中でもデータセンター向けハイエンド品種である「NVIDIA A100 TensorコアGPU」以降が使用されている。しかも、これまでのAI関連処理よりもケタ違いに膨大な数のGPUを使用する。
https://project.nikkeibp.co.jp/onestep/feature/00028/080300001/?P=2
NVIDIAは2024年3月18日(現地時間)、米国サンノゼで開催中のユーザーイベント「GTC(GPU Technology Conference) 2024」(開催期間:同年3月17~21日)の基調講演において、新たなGPUアーキテクチャ「Blackwell」を発表した。浮動小数点演算ベースのAI(人工知能)処理性能で、2022年3月発表の前世代アーキテクチャ「Hopper」の5倍となる20PFLOPSを達成。LLM(大規模言語モデル)など生成AIの処理性能向上にも注力しており、Hopperと比べて学習で4倍、推論実行で30倍、消費電力当たりの処理性能で25倍となっている。Blackwellを採用した製品は2025年後半からの市場投入を予定している。
https://monoist.itmedia.co.jp/mn/articles/2403/19/news091.html
CPUとGPUの違い
- CPUとは、Central Processing Unitの略で、中央演算装置を意味する言葉
- ここのタスクを集中して処理する、連続的な演算能力に長けている
- プログラミングでいう、if の処理が得意
- GPUは、内部でコアが連携して動作することで並列処理が行える
- CPUに比べて圧倒的な処理スピードを誇る
- ただし、単純計算に特化しており、幅広い処理はできない
- プログラミングでいう、forの処理が得意
- ここのタスクを集中して処理する、連続的な演算能力に長けている
スーパコンピュータの多くはGPUを搭載している
- AWSでもEC2からGPUインスタンスを使用することができる https://docs.aws.amazon.com/ja_jp/dlami/latest/devguide/gpu.html
https://balencer.jp/knowledge/nvidia/
ファインチューニング
LLMの一部の再学習を行う。LLM全体の再学習に比べるとコストは抑えることができる。
実際にどのように行うのかについては、以下の通り
- 必要となるモデルをインストールする
- 学習をさせるためのデータセットを準備する
- 収集したデータセットをモデルが理解しやすい形式に変換する → ChatGPTの場合は文章生成AIのため、テキストデータである必要がある
- 事前学習を行なったモデルに対して、収集したデータセットを用いて再学習を行う(この部分をファインチューニングと呼ぶ)
- ファインチューニング後のモデルを評価する
embedding
自然言語を計算が可能な形に変換すること。
ベクトル検索
テキストや画像などのデータを数値ベクトルとして表現
企業がチャットAIを導入する際、「自社内の情報を回答できるようにしたい」というニーズは高い。これを実現するには、「RAG(検索拡張生成)」と呼ばれる仕組み(後日解説予定)を導入するのが一般的だ。そのRAGで自社情報を検索するための方法として、ベクトル検索はよく採用されている。
ベクトル間の類似性
- ユークリッド距離
- 2つの点間の直線最短距離をピタゴラスの定理を用いて測定する方法
- コサイン類似度
- 2つの非ゼロベクトル間の類似度をコサイン角度を用いて計測する
- -1から1の間で変動し、ベクトル間の類似度が高いほど1に近づく
- 2つの非ゼロベクトル間の類似度をコサイン角度を用いて計測する
LangChain
LangChainとは、ChatGPTなどの大規模言語モデルの機能拡張を効率的に実装するためのライブラリ
2024年3月13日時点では、PythonとTypeScriptによるライブラリが公開されている
https://zenn.dev/umi_mori/books/prompt-engineer/viewer/langchain_overview
ベクトルデータベース
生成AIが扱う非構造化データ(テキスト、画像、音声など)の格納、管理、紹介で利用されるデータベース。
pgvector
PostgreSQL上でベクトルデータ型 (vector) を保存し、検索する機能を追加する拡張機能
pgvectorでは、L2距離(<->),内積(<#>),コサイン距離(<=>) によるベクトル距離比較がサポートされている

引用: slideshare.net/slideshow/postgresql-pgvector-chatgpt-pgcon23j-nttdata/263745966
https://qiita.com/yoshiyuki_kono/items/f7cd2a6a2d4fc595f6a8
https://qiita.com/kanaza-s/items/b46214ba8543e34c5003
https://slideshare.net/slideshow/postgresql-pgvector-chatgpt-pgcon23j-nttdata/263745966
日本での生成AI
2024年4月15日 OpenAIが日本語特化で最適化を施した、GPT-4のカスタムモデルを発表した
https://weel.co.jp/media/tech/japanese-gpt-4/
https://openai.com/index/introducing-openai-japan/
活用事例
https://speakerdeck.com/nttcom/how-to-use-generative-ai-in-2024?slide=26
https://www.lycorp.co.jp/ja/story/20240222/ai.html
https://mirai-works.co.jp/business-pro/business-column/generative-ai-case-study
参考資料
ベクトルデータベース
https://weel.co.jp/media/vector-database
https://qiita.com/ksonoda/items/ba6d7b913fc744db3d79
https://www.elastic.co/jp/elasticsearch
ベクトル検索
https://qiita.com/yoshiyuki_kono/items/317aae2830afaef99d8b
エンべディング
https://note.com/eagency/n/nc0d5de8e5535
ファインチューニング
https://qiita.com/ksonoda/items/b9fd3e709aeae79629ff
https://developers.play.jp/entry/2023/10/20/173222
未分類
https://gihyo.jp/article/2023/05/programming-with-chatgpt-03